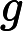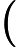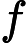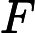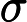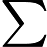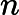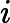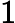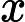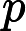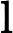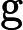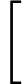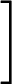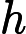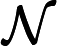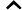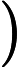डेटा को । अनुभवजन्य वितरण के लिए लिखें । परिभाषा के अनुसार, किसी भी कार्य के लिए ,
























बता दें कि मॉडल का घनत्व जहां को मॉडल के समर्थन पर परिभाषित किया गया है। क्रोस एंट्रोपी की और परिभाषित किया गया है होना करने के लिए
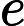








मान लें कि एक सरल यादृच्छिक नमूना है, तो इसका नकारात्मक लॉग संभावना है

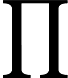


लघुगणक के गुणों के आधार पर (वे उत्पादों को रकम में बदलते हैं)। अभिव्यक्ति एक निरंतर बार अभिव्यक्ति । क्योंकि नुकसान कार्यों को केवल आंकड़ों में तुलना करके उपयोग किया जाता है, इससे कोई फर्क नहीं पड़ता है कि एक दूसरे के प्रति (सकारात्मक) लगातार है। यह इस अर्थ में है कि नकारात्मक लॉग संभावना "उद्धरण में एक क्रॉस-एंट्रोपी है।
कोटेशन के दूसरे दावे को सही ठहराने के लिए थोड़ी और कल्पना की गई है। चुकता त्रुटि के साथ संबंध स्पष्ट है, क्योंकि "Gaussian मॉडल" के लिए, जो बिंदु पर को मान देता है, ऐसे किसी भी बिंदु पर का मान।


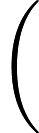



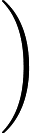
जो चुकता त्रुटि लेकिन द्वारा rescaled और एक फ़ंक्शन द्वारा स्थानांतरित कर दिया गया है । उद्धरण को सही बनाने का एक तरीका यह है कि यह "मॉडल" के भाग पर विचार नहीं करता है - को किसी भी तरह डेटा से स्वतंत्र रूप से निर्धारित किया जाना चाहिए। उस मामले में मतभेद मतलब वर्ग त्रुटियों के बीच के लिए आनुपातिक हैं मतभेद पार entropies या लॉग-likelihoods के बीच है, जिससे मॉडल फिटिंग प्रयोजनों के लिए सभी तीन बराबर बना रही है। 
(आमतौर पर, हालांकि, मॉडलिंग प्रक्रिया के भाग के रूप में फिट है, इस मामले में उद्धरण काफी सही नहीं होगा।)