यह सवाल मेरे वास्तविक भ्रम से उत्पन्न होता है कि कैसे तय किया जाए कि लॉजिस्टिक मॉडल काफी अच्छा है या नहीं। मेरे पास ऐसे मॉडल हैं जो दो साल के बाद वैयक्तिक चर के रूप में बनने के बाद व्यक्तिगत-प्रोजेक्ट जोड़े का उपयोग करते हैं। परिणाम सफल है (1) या नहीं (0)। मेरे पास जोड़े के निर्माण के समय स्वतंत्र चर हैं। मेरा उद्देश्य यह परीक्षण करना है कि क्या एक चर, जिसे मैंने परिकल्पित किया है, जो जोड़े की सफलता को प्रभावित करेगा, उस सफलता पर प्रभाव पड़ता है, अन्य संभावित प्रभावों के लिए नियंत्रित करता है। मॉडलों में, ब्याज का चर महत्वपूर्ण है।
में glm()फ़ंक्शन का उपयोग करके मॉडल का अनुमान लगाया गया था R। मॉडल की गुणवत्ता का मूल्यांकन करने के लिए, मैं कुछ चीजें किया है: glm()आप देता है residual deviance, AICऔर BICडिफ़ॉल्ट रूप से। इसके अलावा, मैंने मॉडल की त्रुटि दर की गणना की है और द्विपदीय अवशिष्टों की साजिश रची है।
- पूर्ण मॉडल में अन्य मॉडलों की तुलना में एक छोटा अवशिष्ट अवशिष्ट, एआईसी और बीआईसी है जो मैंने अनुमान लगाया है (और जो कि पूर्ण मॉडल में नेस्टेड हैं), जो मुझे लगता है कि यह मॉडल दूसरों की तुलना में "बेहतर" है।
- मॉडल की त्रुटि-दर काफी कम है, IMHO (जैसा कि गेलमैन और हिल, 2007, pp.99 ):
error.rate <- mean((predicted>0.5 & y==0) | (predicted<0.5 & y==1)20% पर।
अब तक सब ठीक है। लेकिन जब मैं बिनेड अवशिष्ट (फिर से गेलमैन और हिल की सलाह का पालन करता हूं) की साजिश रचता हूं, तो डिब्बे का एक बड़ा हिस्सा 95% सीआई के बाहर गिर जाता है:
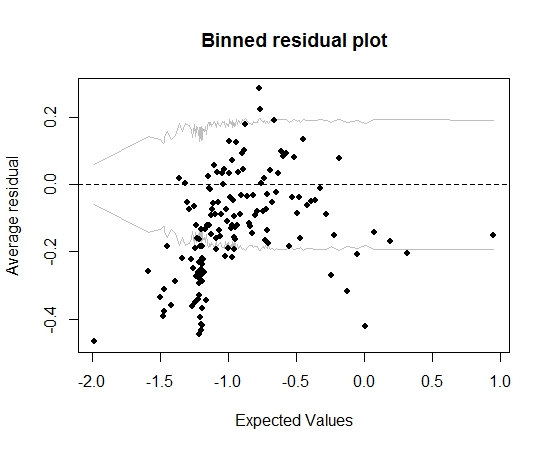
वह कथानक मुझे यह सोचने के लिए प्रेरित करता है कि मॉडल के बारे में कुछ गलत है। क्या मुझे मॉडल को फेंकने के लिए नेतृत्व करना चाहिए? क्या मुझे यह स्वीकार करना चाहिए कि मॉडल अपूर्ण है लेकिन इसे रखें और ब्याज के चर के प्रभाव की व्याख्या करें? मैं बदले में चर को छोड़कर, और कुछ परिवर्तन के साथ भी घूम रहा हूं, बिना द्विज अवशिष्ट प्लॉट में सुधार के।
संपादित करें:
- फिलहाल, मॉडल में एक दर्जन भविष्यवक्ता और 5 इंटरैक्शन प्रभाव हैं।
- जोड़े इस अर्थ में एक-दूसरे से "अपेक्षाकृत" स्वतंत्र होते हैं कि वे सभी थोड़े समय के दौरान बनते हैं (लेकिन कड़े शब्दों में नहीं, सभी एक साथ) और बहुत सारी परियोजनाएं (13k) और बहुत सारे व्यक्ति हैं (19k ), इसलिए परियोजनाओं का एक उचित अनुपात केवल एक व्यक्ति द्वारा शामिल किया गया है (लगभग 20000 जोड़े हैं)।