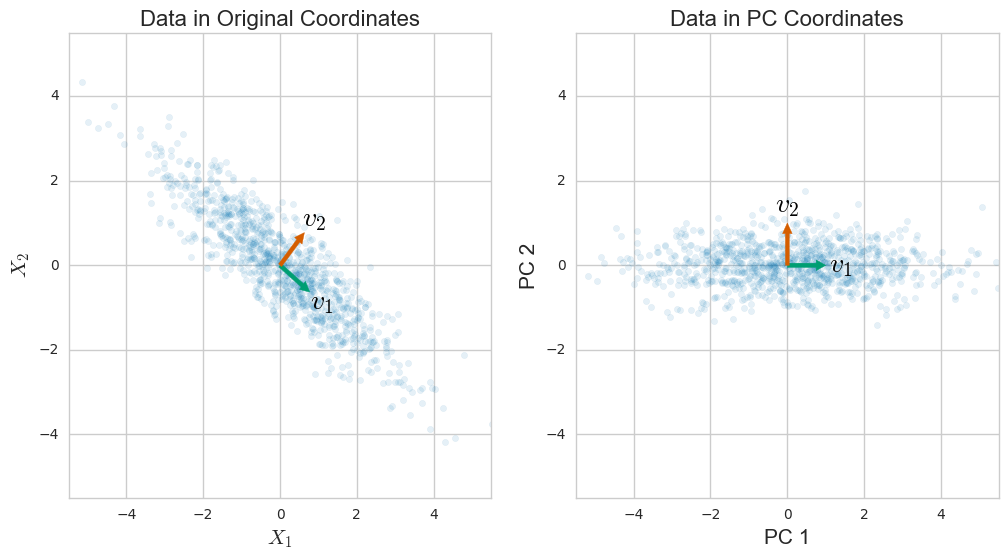
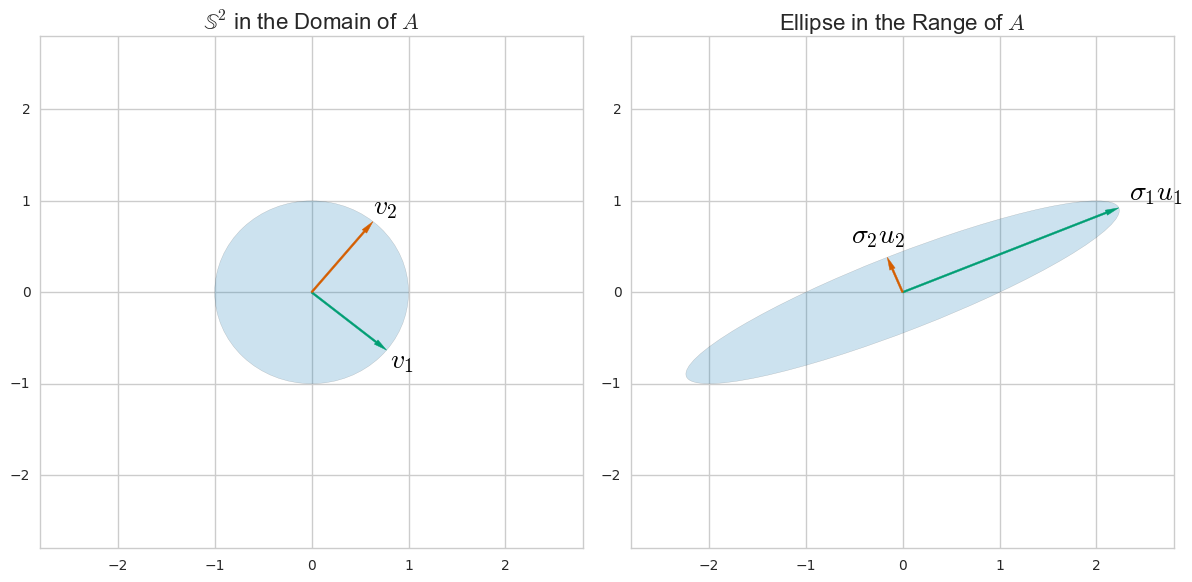
प्रिंसिपल कंपोनेंट एनालिसिस (पीसीए) को आमतौर पर कोवरियन मैट्रिक्स के एक ईजन-अपघटन के माध्यम से समझाया जाता है। हालाँकि, यह डेटा मैट्रिक्स एकवचन मान अपघटन (SVD) के माध्यम से भी किया जा सकता है । यह कैसे काम करता है? इन दोनों दृष्टिकोणों के बीच क्या संबंध है? एसवीडी और पीसीए के बीच क्या संबंध है?
या दूसरे शब्दों में, आयामीता में कमी करने के लिए डेटा मैट्रिक्स के एसवीडी का उपयोग कैसे करें?
8
मैंने अपने स्वयं के उत्तर के साथ इस FAQ-शैली के प्रश्न को एक साथ लिखा था, क्योंकि यह अक्सर विभिन्न रूपों में पूछा जाता है, लेकिन कोई विहित धागा नहीं है और इसलिए डुप्लिकेट को बंद करना मुश्किल है। कृपया इसके साथ मेटा थ्रेड में मेटा टिप्पणी प्रदान करें ।
—
अमीबा
इसके आगे के लिंक के साथ एक उत्कृष्ट और विस्तृत अमीबा के जवाब के अलावा, मैं यह जांचने की सिफारिश कर सकता हूं , जहां पीसीए को कुछ अन्य एसवीडी-आधारित तकनीकों के साथ-साथ माना जाता है। चर्चा बीजगणित लगभग सिर्फ मामूली अंतर के साथ अमीबा के के समान वहाँ प्रस्तुत करता है कि वहाँ भाषण, पीसीए का वर्णन करने में, के SVD अपघटन के बारे में चला जाता है [या ] इसके बजाय - जो बस सुविधाजनक है क्योंकि यह covariance मैट्रिक्स के इगेंडेकोम्पोजिशन के माध्यम से किए गए PCA से संबंधित है। एक्स/ √ एक्स
—
tnnphns
पीसीए एसवीडी का एक विशेष मामला है। पीसीए को डेटा को सामान्यीकृत करने की आवश्यकता है, आदर्श रूप से एक ही इकाई। पीसीए में मैट्रिक्स nxn है।
—
ओरवार कोरवार
@OrvarKorvar: क्या nxn मैट्रिक्स के बारे में बात कर रहे हैं?
—
Cbhihe