केन ने पहले ही अपने जवाब में कुछ कारण बताए । उस पर और विस्तार करने के लिए
- अधिक कैश , जो रैम से तेज है
स्पष्ट रूप से बड़े कैश को अधिक ट्रांजिस्टर की आवश्यकता होती है। लेकिन अधिक ट्रांजिस्टर के साथ हमारे पास तेज कैश का उपयोग करने का विकल्प भी है । CPU कैश सिर्फ SRAM है जो आम तौर पर 6 ट्रांजिस्टर (AKA 6T SRAM) से बनाया जाता है। हालाँकि जब पर्याप्त ट्रांजिस्टर होते हैं तो यह 6 से अधिक ट्रांजिस्टर (जैसे 8T, 10T SRAM) से बने तेज़ लेकिन बड़े SRAM सेल का उपयोग करने लायक हो सकता है।
- अधिक SIMD निर्देश , जो एकल-डेटा निर्देशों की तुलना में तेज़ प्रक्रिया करते हैं
न केवल SIMD बल्कि किसी भी प्रकार के त्वरित निर्देश। उदाहरण के लिए, आधुनिक आर्किटेक्चर में अक्सर तेज एन्क्रिप्शन / डिक्रिप्शन के लिए एईएस यूनिट, बेहतर गणितीय गणना के लिए एफएमए (विशेष रूप से डिजिटल सिग्नल प्रोसेसिंग), या तेज वर्चुअल मशीनों के लिए वर्चुअलाइजेशन होता है। अधिक निर्देशों का समर्थन करने का मतलब है कि उन्हें डीकोड और निष्पादित करने के लिए अधिक संसाधनों की आवश्यकता होती है
- अधिक कोर , इसलिए आप एक ही बार में दो या अधिक काम कर सकते हैं
- पाइपलाइन , इसलिए प्रत्येक कोर एक ही बार में अधिक काम कर सकता है
ये काफी स्पष्ट हैं
- अधिक कार्यात्मक इकाइयां, जैसे अंतर्निहित FPU s, और कई ALU s
अतीत में एफपीयू के लिए पर्याप्त मर क्षेत्र नहीं था, इसलिए लोगों को एक अलग खरीदना चाहिए यदि उनके पास फ्लोटिंग-पॉइंट आर्मीमेट्रिक की उच्च आवश्यकताएं हैं। काफी अधिक ट्रांजिस्टर के साथ यह संभव है कि FPU बिल्ट-इन हो, फ़्लोटिंग-पॉइंट गणित को बहुत तेज़ी से बढ़ाना
इसके अलावा, आधुनिक सीपीयू सुपरस्क्लेयर हैं और स्वतंत्र डेटा टुकड़ों को खोजने के लिए एक साथ कई काम करने की कोशिश करेंगे और उन्हें पहले से गणना करेंगे, भले ही निर्देश धारा रैखिक और धारावाहिक हो। जितना अधिक वे कर सकते हैं समानांतर वे तेजी से करेंगे। ऐसा करने के लिए CPU में कई ALU हो सकते हैं और ALU में कई निष्पादन इकाइयाँ हो सकती हैं। उदाहरण के लिए यदि पिछली पीढ़ी में सीपीयू में 4 की तुलना में 5 जोड़ है तो यह पहले से ही बिना किसी घड़ी के बदलाव के सबसे आशावादी स्थिति में 25% तेजी से चल रहा है। अधिक परिष्कृत सीपीयू भी आउट-ऑफ-ऑर्डर निष्पादन को नियुक्त करते हैं (जो कि अधिकांश आधुनिक उच्च-प्रदर्शन सीपीयू के लिए मामला है)
ऑपरेशन आम तौर पर विभिन्न तरीकों से किए जा सकते हैं। यदि आपके पास अधिक ट्रांजिस्टर हैं, तो आपके पास तेज़ तकनीक का उपयोग करने के लिए अधिक संसाधन होंगे। कुछ सरल उदाहरण:
बिट शिफ्टिंग:
एक साधारण शिफ्टर को धारावाहिक रूप से फ्लिप-फ्लॉप को एक साथ जोड़कर बनाया जाता है।

यह प्रति बिट सिर्फ एक फ्लिप फ्लॉप की जरूरत है, इसलिए बहुत कॉम्पैक्ट है। लेकिन इसे बाईं या दाईं ओर शिफ्ट करने के लिए एक घड़ी की आवश्यकता होती है। यही कारण है कि माइक्रोकंट्रोलर और छोटे एम्बेडेड सीपीयू में केवल एक द्वारा शिफ्ट करने के निर्देश हैं। देख
जब आपके पास खर्च करने के लिए अधिक ट्रांजिस्टर होंगे तो आप बैरल शिफ्टर में बदल सकते हैं । अब एक सीपीयू सैकड़ों या हजारों ट्रांजिस्टर की लागत के साथ एक ही घड़ी में बिट्स को स्थानांतरित कर सकता है
इसके अलावा:
- श्रृंखला में पूर्ण योजक को जोड़कर एक साधारण योजक भी बनाया जाता है । इस तरह एक एन-बिट योजक को अपनी नौकरी खत्म करने के लिए एन घड़ियों की आवश्यकता होती है, जो निश्चित रूप से सीपीयू में लोगों की अपेक्षा नहीं है
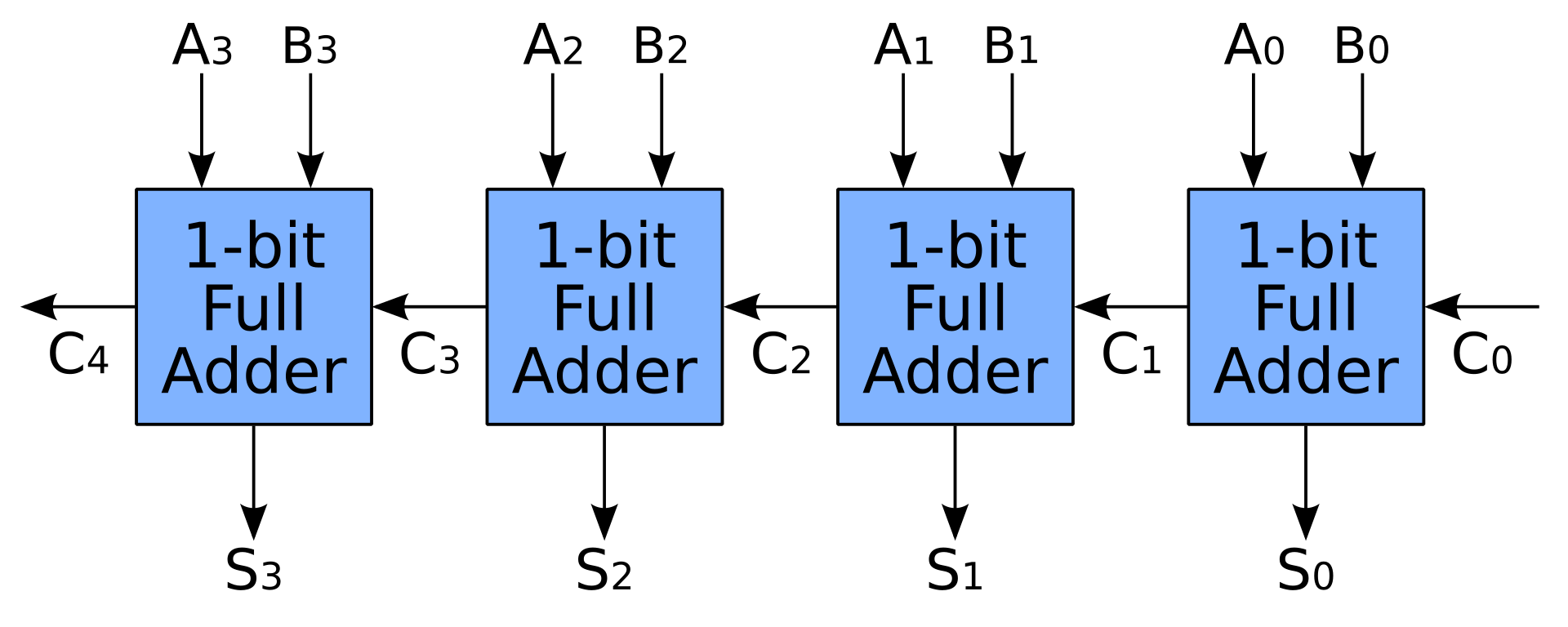
- अधिक ट्रांजिस्टर के साथ हम कैरी को प्री -लुकहेड या कैरी-सेव एडर के साथ कैरी करने की गणना करके तेजी बढ़ा सकते हैं । पूर्ण योजक का उपयोग अभी भी किया जाता है, लेकिन कैरी-प्रीलेअली यूनिट के लिए बहुत अधिक स्थान की आवश्यकता होती है
यही बात मल्टीप्लायरों, डिवाइडर, शेड्यूलर जैसी अन्य इकाइयों पर भी लागू होती है ... उदाहरण के लिए, हम कॉम्बिनेशन लॉजिक का उपयोग करते हुए एक ही घड़ी में कई गुना तेजी से कर सकते हैं । आप प्रश्न 3-बिट गुणक में कुछ सरल उदाहरण देख सकते हैं - वे कैसे काम करते हैं? । लेकिन ट्रांजिस्टर की जरूरत इनपुट चौड़ाई के वर्ग तक बढ़ जाएगी, इसलिए गुणक तर्क के साथ गुणक तर्क वाले छोटे CPU गुणक के लिए बहुत अधिक स्थान बचाने के लिए उपयोग करते हैं:
पुराने गुणक आर्किटेक्चर ने प्रत्येक आंशिक उत्पाद को योग करने के लिए एक शिफ्टर और संचायक को नियोजित किया, अक्सर प्रति चक्र एक आंशिक उत्पाद, डाई क्षेत्र के लिए गति को बंद कर दिया। आधुनिक गुणक वास्तुकला एक चक्र में आंशिक उत्पादों को एक साथ जोड़ने के लिए (संशोधित) बाओ-वोले एल्गोरिथ्म, वालेस के पेड़ या दद्दा गुणक का उपयोग करते हैं। वालेस के पेड़ के कार्यान्वयन का प्रदर्शन कभी-कभी दो बूथों में से एक संशोधित बूथ एन्कोडिंग द्वारा सुधार किया जाता है, जो कि आंशिक उत्पादों की संख्या को कम करता है जिन्हें सारांशित किया जाना चाहिए
https://en.wikipedia.org/wiki/Binary_multiplier#Implementations
एक बार जब आपके पास ट्रांजिस्टर का एक बड़ा पूल होता है, तो आप एफएमए करने के लिए कॉम्बिनेशन लॉजिक का भी उपयोग कर सकते हैं जो कि गुणक से कहीं अधिक संसाधन-गहन है।
आधुनिक कंप्यूटर में एक समर्पित मैक शामिल हो सकता है, जिसमें एक संयोजन में कार्यान्वित एक गुणक शामिल होता है जिसके बाद एक योजक और एक संचायक रजिस्टर होता है जो परिणाम को संग्रहीत करता है। रजिस्टर के आउटपुट को वापस योजक के एक इनपुट पर खिलाया जाता है, ताकि प्रत्येक घड़ी चक्र पर, गुणक के आउटपुट को रजिस्टर में जोड़ा जाए। कॉम्बिनेशन मल्टीप्लायरों को बड़ी मात्रा में तर्क की आवश्यकता होती है, लेकिन पहले के कंप्यूटरों की विशिष्ट शिफ्टिंग और जोड़ने की विधि की तुलना में बहुत अधिक तेज़ी से किसी उत्पाद की गणना कर सकते हैं।
गुणा-संचय ऑपरेशन

#/media/File:1-bit_full-adder.svg)