मैंने महीनों तक यह सवाल किया है। ऐसा लगता है जैसे हमने सॉफ्टमैक्स को केवल एक आउटपुट फ़ंक्शन के रूप में अनुमान लगाया है और फिर लॉग-प्रायिकता के रूप में सॉफ्टमैक्स पर इनपुट की व्याख्या करते हैं। जैसा कि आपने कहा, क्यों नहीं सभी योगों को उनकी राशि से विभाजित करके सामान्य किया जाए? मुझे दीप लर्निंग पुस्तक में गुडफेलो, बेंगियो और कोर्टविल (2016) द्वारा खंड 6.2.2 में उत्तर मिला।
मान लीजिए कि हमारी अंतिम छिपी हुई परत हमें सक्रियण के रूप में z देती है। फिर सॉफ्टमैक्स को परिभाषित किया गया है

बहुत छोटी व्याख्या
सॉफ्टमैक्स फंक्शन में विस्तार, क्रॉस-एन्ट्रापी लॉस में लॉग को लगभग रद्द कर देता है, जिससे नुकसान z_i में लगभग रैखिक हो जाता है। यह मोटे तौर पर निरंतर ढाल की ओर जाता है, जब मॉडल गलत होता है, जिससे यह जल्दी से सही होने की अनुमति देता है। इस प्रकार, एक गलत संतृप्त सॉफ्टमैक्स एक लुप्तप्राय ढाल का कारण नहीं बनता है।
संक्षिप्त व्याख्या
तंत्रिका नेटवर्क को प्रशिक्षित करने के लिए सबसे लोकप्रिय विधि अधिकतम संभावना अनुमान है। हम एक तरह से पैरामीटर थीटा का अनुमान लगाते हैं जो प्रशिक्षण डेटा (आकार एम के) की संभावना को अधिकतम करता है। क्योंकि संपूर्ण प्रशिक्षण डेटासेट की संभावना प्रत्येक नमूने की संभावना का एक उत्पाद है, इसलिए डेटासेट की लॉग-लाइबिलिटी को अधिकतम करना आसान है और इस प्रकार k द्वारा अनुक्रमित प्रत्येक नमूने की लॉग-लाइबिलिटी का योग:
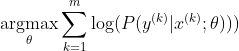
अब, हम केवल पहले से दिए गए z के साथ यहां सॉफ्टमैक्स पर ध्यान केंद्रित करते हैं, इसलिए हम बदल सकते हैं
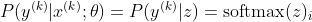
मैं kth नमूने का सही वर्ग होने के साथ। अब, हम देखते हैं कि जब हम नमूने के लॉग-लिक्विडिटी की गणना करने के लिए सॉफ्टमैक्स का लॉगरिदम लेते हैं, तो हम:
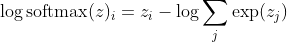
, जो z में बड़े अंतर के लिए लगभग सन्निकट है
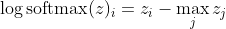
सबसे पहले, हम यहाँ रैखिक घटक z_i देखते हैं। दूसरे, हम दो मामलों के लिए अधिकतम (z) के व्यवहार की जांच कर सकते हैं:
- यदि मॉडल सही है, तो अधिकतम (z) z_i होगा। इस प्रकार, z-i और z में अन्य प्रविष्टियों के बीच बढ़ते अंतर के साथ लॉग-लाइबिलिटी asymptotes शून्य (अर्थात 1 की संभावना) है।
- यदि मॉडल गलत है, तो अधिकतम (z) कुछ अन्य z_j> z_i होगा। तो, z_i का जोड़ पूरी तरह से -z_j को रद्द नहीं करता है और लॉग-लाइबिलिटी लगभग (z_i - z_j) है। यह स्पष्ट रूप से मॉडल को बताता है कि लॉग-लाइक बढ़ाने के लिए क्या करना चाहिए: z_i बढ़ाएं और z_j घटाएं।
हम देखते हैं कि समग्र लॉग-आउट की संभावना नमूने पर हावी होगी, जहां मॉडल गलत है। इसके अलावा, भले ही मॉडल वास्तव में गलत हो, जो संतृप्त सॉफ्टमैक्स की ओर जाता है, नुकसान फ़ंक्शन संतृप्त नहीं करता है। यह z_j में लगभग रैखिक है, जिसका अर्थ है कि हमारे पास लगभग स्थिर ढाल है। यह मॉडल को जल्दी से सही करने की अनुमति देता है। ध्यान दें कि उदाहरण के लिए माध्य चुकता त्रुटि के लिए यह मामला नहीं है।
लंबी व्याख्या
यदि सॉफ्टमैक्स आपको अभी भी एक मनमानी पसंद लगता है, तो आप लॉजिस्टिक रिग्रेशन में सिग्मोइड का उपयोग करने के औचित्य पर एक नज़र डाल सकते हैं:
कुछ और के बजाय सिग्मोइड फ़ंक्शन क्यों?
सॉफ्टमैक्स बहु-वर्ग समस्याओं के लिए सिग्मॉइड का सामान्यीकरण है जो उचित रूप से उचित है।



