मुझे एक डोमेन नाम मान्य करने की आवश्यकता है:
Google.com
stackoverflow.com
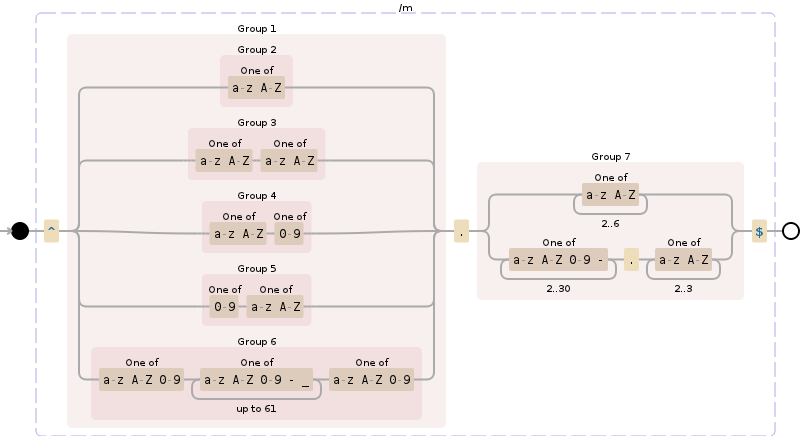
तो अपने कच्चे रूप में एक डोमेन - www की तरह एक उपडोमेन भी नहीं।
- अक्षर केवल az होना चाहिए | AZ | 0-9 और अवधि (?) और डैश (-)
- डोमेन नाम का हिस्सा डैश (-) (जैसे -google-.com) के साथ शुरू या समाप्त नहीं होना चाहिए
- डोमेन नाम भाग 1 और 63 वर्णों के बीच होना चाहिए
विस्तार (TLD) अभी के लिए # 1 नियमों के तहत कुछ भी हो सकता है, मैं उन्हें बाद में एक सूची के खिलाफ मान्य कर सकता हूं, हालांकि यह 1 या अधिक वर्ण होना चाहिए
संपादित करें: TLD स्पष्ट रूप से 2-6 वर्ण है क्योंकि यह खड़ा है
नहीं। 4 संशोधित: TLD को वास्तव में "उपडोमेन" लेबल किया जाना चाहिए क्योंकि इसमें .co.uk जैसी चीजें शामिल होनी चाहिए - मैं केवल एक ही सत्यापन संभव होगा (एक सूची के खिलाफ जांच के अलावा) 'पहले बिंदु के बाद एक या एक होना चाहिए' नियम # 1 के तहत अधिक वर्ण
बहुत बहुत धन्यवाद, मुझे विश्वास है कि मैंने कोशिश की थी!
1
हो सकता है मददगार न हों। जब यह google.co.uk, और कुछ जापानी डोमेन की बात आती है, तो मुझे यकीन है कि इसके लिए regex का उपयोग करने से पहले आपको दो बार सोचना होगा। मेरा व्यक्तिगत विचार यह है कि regex एक डोमेन को वास्तविक जीवन के डोमेन को मान्य करने के लिए पर्याप्त नहीं है। FYI करें, यहाँ टॉरेट्स और कंट्री कोड सेकंड लेवल डोमेन लिस्ट की लगभग पूरी सूची है: static.ayesh.me/misc/SO/tlds.txt
—
K
होस्टनाम सत्यापन के बारे में संबंधित प्रश्न के लिए मेरा उत्तर देखें ।
—
एसएएम
अक्सर भूल गए: पूर्ण योग्य डोमेन नामों के लिए आपको tld के बाद की अवधि से मेल खाना चाहिए।
—
schmijos
4 साल हो गए हैं, अब गिनती 89,000 तक है
—
mydoglixu
इनमें से कुछ उत्तर बहुत अच्छे हैं, लेकिन इस अन्य प्रश्न पर एक और अच्छा उत्तर है जो देखने लायक है।
—
craftworkgames