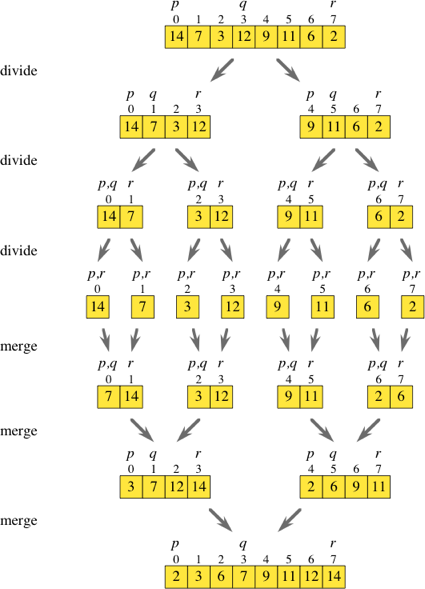
तो मर्ज सॉर्ट एक विभाजित और एल्गोरिथ्म को जीत है। जब मैं उपरोक्त आरेख को देख रहा था, तो मैं सोच रहा था कि क्या मूल रूप से सभी विभाजन चरणों को बायपास करना संभव है।
यदि आप दो से कूदते समय मूल सरणी पर पुनरावृत्त होते हैं, तो आप तत्वों को इंडेक्स i और i + 1 पर प्राप्त कर सकते हैं और उन्हें अपने स्वयं के क्रमबद्ध सरणियों में डाल सकते हैं। एक बार जब आप इन सभी उप-सरणियों ([7,14], [3,12], [9,11] और [2,6] जैसा कि आरेख में दिखाया गया है), आप बस सामान्य मर्ज दिनचर्या के साथ आगे बढ़ सकते हैं एक क्रमबद्ध सरणी।
क्या सरणी के माध्यम से पुनरावृत्ति हो रही है और तुरंत आवश्यक उप-सरणियों को कम करने से उनकी संपूर्णता में विभाजन के चरणों का प्रदर्शन करने की तुलना में कम कुशल है?
संबंधित: cs.stackexchange.com/questions/77075/...
—
उमर