दुनिया भर के स्कूलों में, बच्चे अपने एलसीडी कैलकुलेटर में एक नंबर टाइप करते हैं, इसे उल्टा करते हैं और 'बूबीज़' शब्द बनाने के बाद हँसी में फट जाते हैं। बेशक, यह सबसे लोकप्रिय शब्द है, लेकिन कई अन्य शब्द भी हैं जिनका उत्पादन किया जा सकता है।
सभी शब्द 10 अक्षरों से कम लंबे होने चाहिए, हालांकि (शब्दकोश में हालांकि इससे लंबे शब्द हैं, इसलिए आपको अपने कार्यक्रम में एक फ़िल्टर करना होगा)। इस शब्दकोश में, कुछ बड़े शब्द हैं, इसलिए सभी शब्दों को लोअरकेस में बदल दें।
एक अंग्रेजी भाषा के शब्दकोश का उपयोग करते हुए, संख्याओं की एक सूची बनाएं जो एक एलसीडी कैलकुलेटर में टाइप की जा सकती है और एक शब्द बनाती है। सभी कोड गोल्फ सवालों के साथ, इस कार्य को पूरा करने वाला सबसे छोटा प्रोग्राम जीत जाता है।
अपने परीक्षणों के लिए, मैंने टाइप करके एकत्रित UNIX शब्द सूची का उपयोग किया:
ln -s /usr/dict/words w.txt
या वैकल्पिक रूप से, इसे यहां प्राप्त करें ।
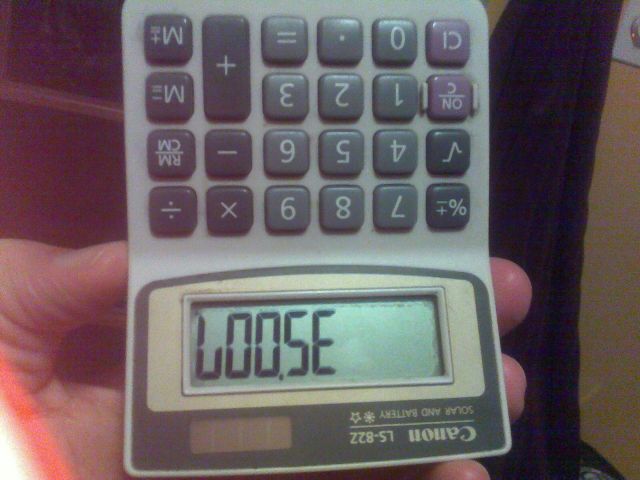
उदाहरण के लिए, ऊपर की छवि 35007कैलकुलेटर में संख्या टाइप करके और इसे उल्टा करके बनाई गई थी ।
पत्र और उनके संबंधित नंबर:
- बी :
8 - जी :
6 - एल :
7 - मैं :
1 - ओ :
0 - s :
5 - z :
2 - ज :
4 - ई :
3
ध्यान दें कि यदि संख्या शून्य से शुरू होती है, तो उस शून्य के बाद एक दशमलव बिंदु आवश्यक है। संख्या को दशमलव बिंदु से शुरू नहीं करना चाहिए।
मुझे लगता है कि यह मार्टिनबटनर का कोड है, बस आप इसके लिए श्रेय लेना चाहते थे :)
/* Configuration */
var QUESTION_ID = 51871; // Obtain this from the url
// It will be like http://XYZ.stackexchange.com/questions/QUESTION_ID/... on any question page
var ANSWER_FILTER = "!t)IWYnsLAZle2tQ3KqrVveCRJfxcRLe";
/* App */
var answers = [], page = 1;
function answersUrl(index) {
return "http://api.stackexchange.com/2.2/questions/" + QUESTION_ID + "/answers?page=" + index + "&pagesize=100&order=desc&sort=creation&site=codegolf&filter=" + ANSWER_FILTER;
}
function getAnswers() {
jQuery.ajax({
url: answersUrl(page++),
method: "get",
dataType: "jsonp",
crossDomain: true,
success: function (data) {
answers.push.apply(answers, data.items);
if (data.has_more) getAnswers();
else process();
}
});
}
getAnswers();
var SIZE_REG = /\d+(?=[^\d&]*(?:<(?:s>[^&]*<\/s>|[^&]+>)[^\d&]*)*$)/;
var NUMBER_REG = /\d+/;
var LANGUAGE_REG = /^#*\s*([^,]+)/;
function shouldHaveHeading(a) {
var pass = false;
var lines = a.body_markdown.split("\n");
try {
pass |= /^#/.test(a.body_markdown);
pass |= ["-", "="]
.indexOf(lines[1][0]) > -1;
pass &= LANGUAGE_REG.test(a.body_markdown);
} catch (ex) {}
return pass;
}
function shouldHaveScore(a) {
var pass = false;
try {
pass |= SIZE_REG.test(a.body_markdown.split("\n")[0]);
} catch (ex) {}
return pass;
}
function getAuthorName(a) {
return a.owner.display_name;
}
function process() {
answers = answers.filter(shouldHaveScore)
.filter(shouldHaveHeading);
answers.sort(function (a, b) {
var aB = +(a.body_markdown.split("\n")[0].match(SIZE_REG) || [Infinity])[0],
bB = +(b.body_markdown.split("\n")[0].match(SIZE_REG) || [Infinity])[0];
return aB - bB
});
var languages = {};
var place = 1;
var lastSize = null;
var lastPlace = 1;
answers.forEach(function (a) {
var headline = a.body_markdown.split("\n")[0];
//console.log(a);
var answer = jQuery("#answer-template").html();
var num = headline.match(NUMBER_REG)[0];
var size = (headline.match(SIZE_REG)||[0])[0];
var language = headline.match(LANGUAGE_REG)[1];
var user = getAuthorName(a);
if (size != lastSize)
lastPlace = place;
lastSize = size;
++place;
answer = answer.replace("{{PLACE}}", lastPlace + ".")
.replace("{{NAME}}", user)
.replace("{{LANGUAGE}}", language)
.replace("{{SIZE}}", size)
.replace("{{LINK}}", a.share_link);
answer = jQuery(answer)
jQuery("#answers").append(answer);
languages[language] = languages[language] || {lang: language, user: user, size: size, link: a.share_link};
});
var langs = [];
for (var lang in languages)
if (languages.hasOwnProperty(lang))
langs.push(languages[lang]);
langs.sort(function (a, b) {
if (a.lang > b.lang) return 1;
if (a.lang < b.lang) return -1;
return 0;
});
for (var i = 0; i < langs.length; ++i)
{
var language = jQuery("#language-template").html();
var lang = langs[i];
language = language.replace("{{LANGUAGE}}", lang.lang)
.replace("{{NAME}}", lang.user)
.replace("{{SIZE}}", lang.size)
.replace("{{LINK}}", lang.link);
language = jQuery(language);
jQuery("#languages").append(language);
}
}body { text-align: left !important}
#answer-list {
padding: 10px;
width: 50%;
float: left;
}
#language-list {
padding: 10px;
width: 50%px;
float: left;
}
table thead {
font-weight: bold;
}
table td {
padding: 5px;
}<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<link rel="stylesheet" type="text/css" href="//cdn.sstatic.net/codegolf/all.css?v=83c949450c8b">
<div id="answer-list">
<h2>Leaderboard</h2>
<table class="answer-list">
<thead>
<tr><td></td><td>Author</td><td>Language</td><td>Size</td></tr>
</thead>
<tbody id="answers">
</tbody>
</table>
</div>
<div id="language-list">
<h2>Winners by Language</h2>
<table class="language-list">
<thead>
<tr><td>Language</td><td>User</td><td>Score</td></tr>
</thead>
<tbody id="languages">
</tbody>
</table>
</div>
<table style="display: none">
<tbody id="answer-template">
<tr><td>{{PLACE}}</td><td>{{NAME}}</td><td>{{LANGUAGE}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr>
</tbody>
</table>
<table style="display: none">
<tbody id="language-template">
<tr><td>{{LANGUAGE}}</td><td>{{NAME}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr>
</tbody>
</table>0.7734के लिए नमस्ते या होगा .7734स्वीकार्य हो?
0.7734की आवश्यकता है
oligo एक अनुगामी शून्य की आवश्यकता होती है :0.6170